Getting Started with Inspect-AI
Evaluating LLM Code Generation
Welcome!
Prerequisites
- Basic Python knowledge
- Familiarity with LLMs (ChatGPT, Claude, etc.)
- No prior experience with
inspect-aineeded!
What is Inspect-AI?
The Problem
LLMs are everywhere, but how do we know if they’re doing a good job?
- Manual testing is time-consuming
- Hard to compare different models
- Inconsistent evaluation criteria
- No systematic way to track improvements
The Solution: Inspect-AI
A framework for systematic LLM evaluation
- Automated testing of LLM responses
- Consistent evaluation across models
- Reproducible results you can share
- Scalable from single tests to large benchmarks
Key Concepts
🎯 Task - The Complete Exam Setup
What it is: The entire exam - combines all the pieces together
Real-world analogy: Like organizing a math test with questions, answer key, and grading rubric
Why you need it: Without a Task, you’d just have loose pieces - questions without a test format, no way to run the evaluation.
📚 Dataset - The Test Questions
What it is: A collection of questions and their correct answers
Real-world analogy: Like a teacher’s question bank with answer key
Why you need it: Without questions, what would you test the AI on? The dataset defines what skills you’re evaluating.
🤖 Solver - The Student Taking the Test
What it is: The AI model you want to evaluate (GPT-5, Claude, etc.)
Real-world analogy: Like the student sitting for the exam
Common beginner confusion:
✅ Solver = The AI being tested (the student)
❌ Not the grading system (that’s the scorer)
📝 Scorer - The Teacher Grading the Test
What it is: The function that decides if the AI’s answer is right or wrong
Real-world analogy: Like a teacher with a red pen grading student papers
Types of Scoring:
Simple Scoring (Exact Match)
Example: “What is 2+2?” → Only “4” is correct, “four” would be wrong
Smart Scoring (AI Grader)
Example: “Write a story” → AI grader reads the story and decides if it’s creative and well-written
Why you need it: Without a grader, you can’t tell if the AI did well or poorly!
Our Example: Tip Calculator
The Challenge
We want to test if an LLM can generate working Shiny for Python code for a tip calculator app.
Requirements:
- Input fields for bill amount and slider for tip percentage
- Calculation logic to compute tip amount and total
- Display of calculated results
- Should allow ability to split tips among n people
- Should not use
@outputin server functions
Sample Expected Output
Setting Up the Evaluation
Step 1: Open a Positron session in Workbench
- Navigate to Posit Okta page
- Launch Positron in Workbench
- Create a new directory called eval_workshop
- Open a terminal in Positron and navigate to eval_workshop directory
- Create a virtual environment and activate it by typing
Step 2: Install Inspect-AI
Step 3: Create a new file named shiny_app_eval.py in this directory and copy this code
# shiny_app_eval.py
from inspect_ai import Task, task
from inspect_ai.dataset import Sample
from inspect_ai.model import get_model
from inspect_ai.scorer import model_graded_qa, accuracy
from inspect_ai.solver import generate, system_message
DESIRED_RESPONSE = (
"A functional Shiny for Python tip calculator app that includes:\n"
"1. Input fields for bill amount and tip percentage\n"
"2. Calculation logic to compute tip amount and total\n"
"3. Display of calculated results\n"
"4. Should allow ability to split tips among n people\n"
"5. Should not use @output in server functions"
)
CUSTOM_INSTRUCTIONS = """
Please evaluate the provided answer against the given criterion using chain-of-thought reasoning.
First, analyze the answer step by step:
1. Check if it includes input fields for bill amount and tip percentage
2. Verify there is calculation logic for tip amount and total
3. Confirm it displays calculated results
4. Check if it allows splitting tips among n people
5. Verify it does not use @output in server functions
Then provide your reasoning for the grade, explaining what the answer does well and what it might be missing.
Finally, provide your grade in the format: GRADE: C (for correct) , GRADE: P (for partial) or GRADE: I (for incorrect).
"""
CLAUDE_SONNET_3_7 = "anthropic/bedrock/us.anthropic.claude-3-7-sonnet-20250219-v1:0"
CLAUDE_HAIKU_3_5 = "anthropic/bedrock/us.anthropic.claude-3-5-haiku-20241022-v1:0"
@task
def tip_calculator_task():
return Task(
dataset=[
Sample(
input="Create a Shiny for Python tip calculator app with "
"outputs showing tip amount and total.",
target=DESIRED_RESPONSE,
id="tip_calculator_001",
)
],
solver=[
generate()
],
scorer=model_graded_qa(
instructions=CUSTOM_INSTRUCTIONS,
partial_credit=True,
model=[
CLAUDE_SONNET_3_7,
CLAUDE_HAIKU_3_5,
],
),
metrics=[accuracy()],
model=get_model(CLAUDE_SONNET_3_7),
)Step 4: Run the Evaluation
Step 5: Evaluate log file in json format
- Check the
metadata->grading->content->textkey within the json to see the content of the grading
Improving the scorer
Use the improved code to get a higher quality result
Diff between previous and current iteration of code
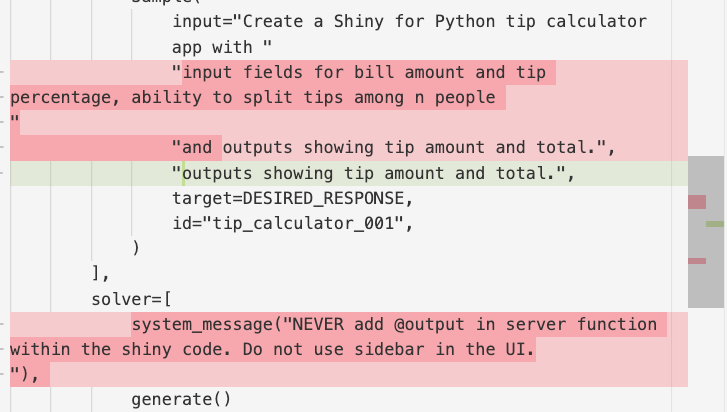
from inspect_ai import Task, task
from inspect_ai.dataset import Sample
from inspect_ai.model import get_model
from inspect_ai.scorer import model_graded_qa, accuracy
from inspect_ai.solver import generate, system_message
DESIRED_RESPONSE = (
"A functional Shiny for Python tip calculator app that includes:\n"
"1. Input fields for bill amount and tip percentage\n"
"2. Calculation logic to compute tip amount and total\n"
"3. Display of calculated results\n"
"4. Should allow ability to split tips among n people\n"
"5. Should not use @output in server functions"
)
CUSTOM_INSTRUCTIONS = """
Please evaluate the provided answer against the given criterion using chain-of-thought reasoning.
First, analyze the answer step by step:
1. Check if it includes input fields for bill amount and tip percentage
2. Verify there is calculation logic for tip amount and total
3. Confirm it displays calculated results
4. Check if it allows splitting tips among n people
5. Verify it does not use @output in server functions
Then provide your reasoning for the grade, explaining what the answer does well and what it might be missing.
Finally, provide your grade in the format: GRADE: C (for correct) , GRADE: P (for partial) or GRADE: I (for incorrect).
"""
CLAUDE_SONNET_3_7 = "anthropic/bedrock/us.anthropic.claude-3-7-sonnet-20250219-v1:0"
CLAUDE_HAIKU_3_5 = "anthropic/bedrock/us.anthropic.claude-3-5-haiku-20241022-v1:0"
@task
def tip_calculator_task():
return Task(
dataset=[
Sample(
input="Create a Shiny for Python tip calculator app with "
"input fields for bill amount and tip percentage, ability to split tips among n people "
"and outputs showing tip amount and total.",
target=DESIRED_RESPONSE,
id="tip_calculator_001",
)
],
solver=[
system_message("NEVER add @output in server function within the shiny code. Do not use sidebar in the UI."),
generate()
],
scorer=model_graded_qa(
instructions=CUSTOM_INSTRUCTIONS,
partial_credit=True,
model=[
CLAUDE_SONNET_3_7,
CLAUDE_HAIKU_3_5,
],
),
metrics=[accuracy()],
model=get_model(CLAUDE_SONNET_3_7),
)Another example that needs tool calling
from inspect_ai import Task, task
from inspect_ai.dataset import Sample
from inspect_ai.model import get_model
from inspect_ai.scorer import match
from inspect_ai.solver import generate, system_message, use_tools
from inspect_ai.tool import tool
CLAUDE_HAIKU_3_5 = "anthropic/bedrock/us.anthropic.claude-3-5-haiku-20241022-v1:0"
def create_weather_dataset():
return [
Sample(
input="What's the weather like in New York?", target="Partly cloudy, 68°F"
),
Sample(input="How's the weather in Miami?", target="Hot and humid, 85°F"),
Sample(input="What's the current weather in Chicago?", target="Windy, 58°F"),
Sample(
input="Tell me the weather forecast for Los Angeles", target="Sunny, 75°F"
),
Sample(input="What's it like outside in Seattle?", target="Drizzling, 54°F"),
]
@task
def weather_lookup_task():
"""
A task that tests if an AI can use a weather lookup tool
to get weather information for different locations.
"""
return Task(
# Our dataset of weather questions
dataset=create_weather_dataset(),
solver=[
system_message(
"You are a helpful weather assistant."
),
generate(),
],
scorer=match(),
model=get_model(CLAUDE_HAIKU_3_5),
)Improved code for higher quality result
from inspect_ai import Task, task
from inspect_ai.dataset import Sample
from inspect_ai.model import get_model
from inspect_ai.scorer import match
from inspect_ai.solver import generate, system_message, use_tools
from inspect_ai.tool import tool
CLAUDE_HAIKU_3_5 = "anthropic/bedrock/us.anthropic.claude-3-5-haiku-20241022-v1:0"
@tool
def weather_lookup():
async def execute(location: str):
"""
A hypothetical weather lookup tool that provides weather information based on location.
Args:
location: A location name (city, state, or region) to get weather for
Returns:
Weather information for the specified location
"""
# Hypothetical weather data based on different regions/cities
weather_data = {
# Northeast
"new york": "Partly cloudy, 68°F",
"boston": "Rainy, 62°F",
"philadelphia": "Sunny, 72°F",
# Southeast
"miami": "Hot and humid, 85°F",
"atlanta": "Thunderstorms, 78°F",
"orlando": "Sunny, 82°F",
# Midwest
"chicago": "Windy, 58°F",
"detroit": "Overcast, 55°F",
"minneapolis": "Snow flurries, 35°F",
# West Coast
"los angeles": "Sunny, 75°F",
"san francisco": "Foggy, 62°F",
"seattle": "Drizzling, 54°F",
# Southwest
"phoenix": "Very hot, 102°F",
"denver": "Clear skies, 65°F",
"las vegas": "Extremely hot, 108°F",
# Texas
"houston": "Humid, 88°F",
"dallas": "Hot, 95°F",
"austin": "Warm, 86°F",
}
location_lower = location.lower().strip()
if location_lower in weather_data:
return f"Weather in {location.title()}: {weather_data[location_lower]}"
else:
return f"Weather data not available for '{location}'. Try a major US city."
return execute
def create_weather_dataset():
return [
Sample(
input="What's the weather like in New York?", target="Partly cloudy, 68°F"
),
Sample(input="How's the weather in Miami?", target="Hot and humid, 85°F"),
Sample(input="What's the current weather in Chicago?", target="Windy, 58°F"),
Sample(
input="Tell me the weather forecast for Los Angeles", target="Sunny, 75°F"
),
Sample(input="What's it like outside in Seattle?", target="Drizzling, 54°F"),
]
@task
def weather_lookup_task():
"""
A task that tests if an AI can use a weather lookup tool
to get weather information for different locations.
"""
return Task(
# Our dataset of weather questions
dataset=create_weather_dataset(),
solver=[
system_message(
"You are a helpful weather assistant. When asked about weather, "
"use the weather_lookup tool to get current weather information. "
"After using the tool, provide ONLY the weather information (no extra text)."
),
use_tools([weather_lookup()]),
generate(),
],
scorer=match(),
model=get_model(CLAUDE_HAIKU_3_5),
)Hands-On Time!
Your Turn
- Set up
inspect-aiin your environment - Create a simple evaluation for code generation
- Run the evaluation with a model of your choice
- Analyze the results